Towards foundational LiDAR world models
with efficient latent flow matching
University of Toronto
Abstract
LiDAR-based world models offer more structured and geometry-aware representations than their image-based counterparts. However, existing LiDAR world models are narrowly trained; each model excels only in the domain for which it was built.
Can we develop LiDAR world models that exhibit strong transferability across multiple domains?
We conduct the first systematic domain-transfer study across three demanding scenarios: (i) outdoor-to-indoor generalization, (ii) sparse-beam & dense-beam adaptation, and (iii)
non-semantic-to-semantic transfer.
Across different fine-tuning budgets, a single pre-trained model attains up to 11% absolute (83% relative) improvement over training from scratch and wins in 30/36 comparisons.
This transferability dramatically reduces reliance on manual annotation for semantic occupancy forecasting: our method surpasses previous models using only 5% of the labeled data they require.
We also identify inefficiencies in current LiDAR world models—chiefly under-compression of LiDAR data and sub‑optimal training objectives. To tackle this, we introduce a latent conditional flow‑matching (CFM)
framework that reaches state‑of‑the‑art reconstruction accuracy with 50% the training data and a 6x higher compression ratio than prior work.
Our model delivers SOTA performance on trajectory- conditioned semantic occupancy forecasting while being 23× more computationally efficient (28× FPS speed‑up),
and achieves SOTA performance on unconditional semantic occupancy forecasting with 2x computational efficiency (1.1x FPS speed‑up).
Method
We attribute the inefficiency of existing models to redundant model parameters and excessive training time. In order to facilitate systematic analyse of the transferability of dynamic learning, we first need to alleviate these two issues by a new data compressor and introduction of flow matching.
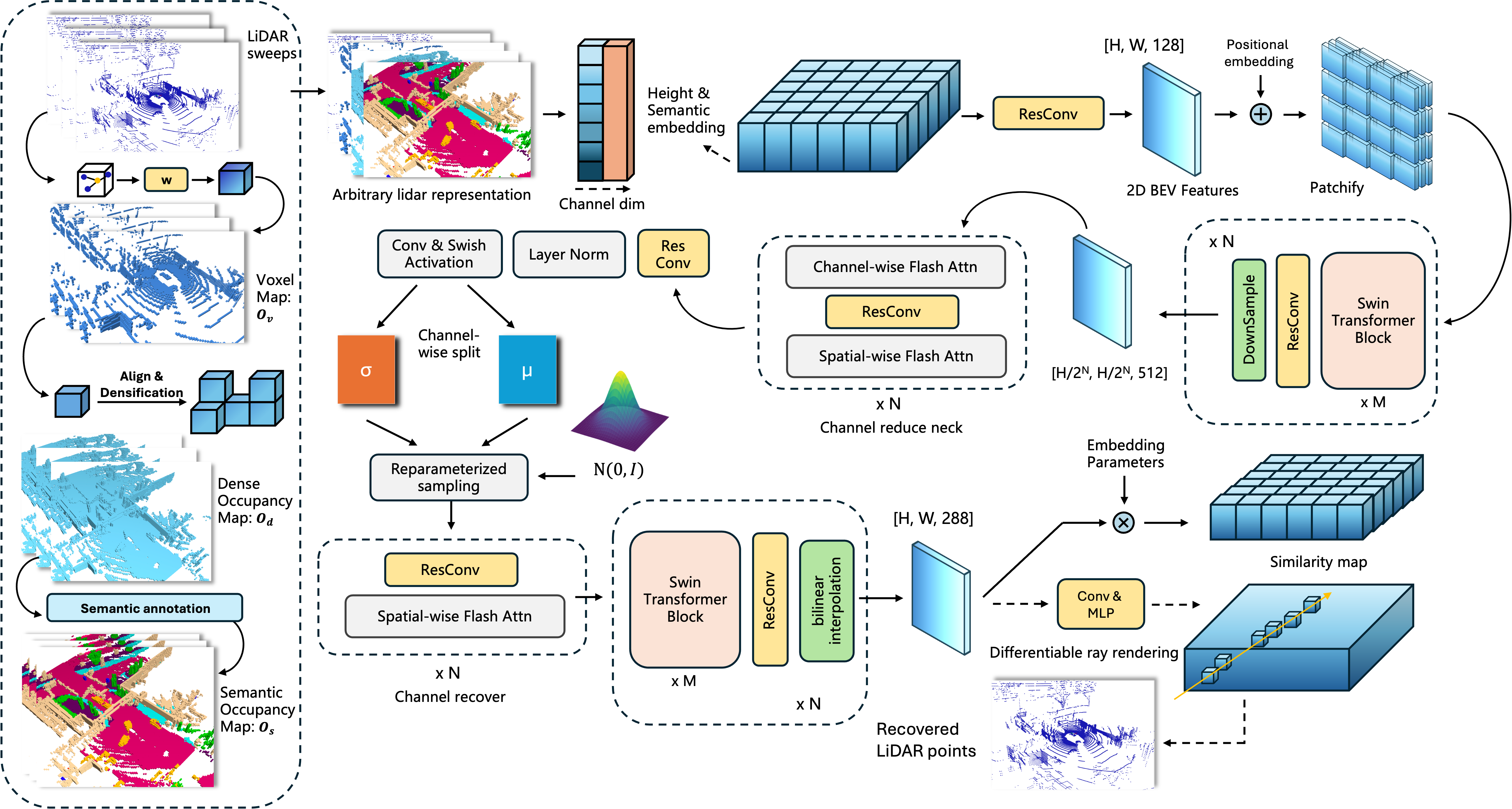
We abandoned the autoencoder based on the Stable Diffusion 3 VAE structure used in almost all previous work. The newly proposed VAE can not only compress arbitrary voxel-based LiDAR representation at a higher compression ratio , but also with less reconstruction loss .

The proposed CFM-based method obtained SOTA accuracy in both semantic occupancy forecasting w/w.o trajectory. Our method also demonstrates faster convergence speed and sample efficiency: Our method only requires 200 epochs of training to exceed the results that previously required thousands of epochs to achieve. The model only have 30.37M parameters
Main results
Cross domain analyse: dynamic pretraining for 3 subtasks
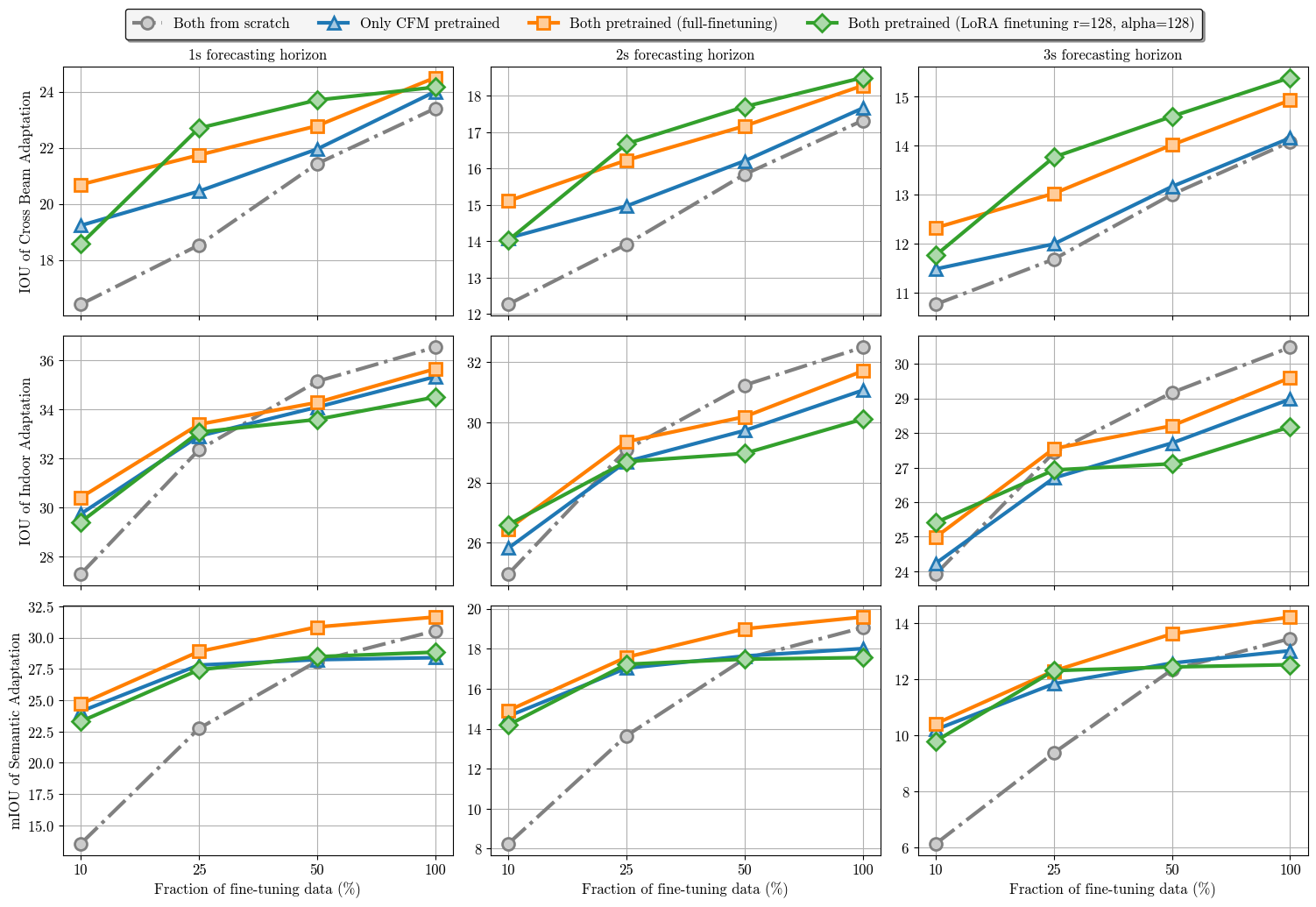
We report IOU/mIOU for every subtasks on different fine-turning data fractions w./w.o. pretraining. An up to 83% relative improvement (1s forecasting on semantic occupancy) can be observed among all of the experiments.
This outstanding transferability validates our designed pipeline learnt the prior dynamic knowledge, which can be useful in downstream tasks which suffering from data availability or expensive human annotation
Interestingly, here when we use only 10% of fine-turning data on semantic occupancy forecasting task (which is 5% of full training set of nuScense,
see paper for detail), the performance of model with pretrained dynamic learning module have exceeded the OccWorld.
Preformance evaluation
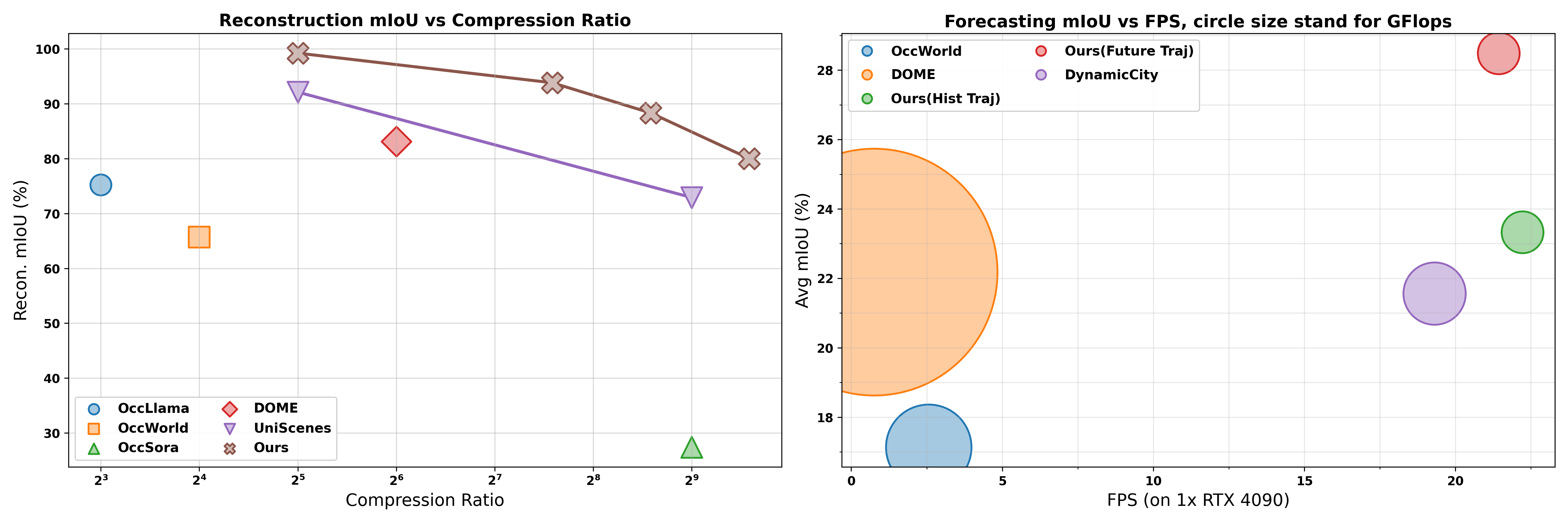
From 32x compression ratio to even 768x, our proposed data compressor have SOTA performance - far from autoencoder used in previous SOTA method (left figure). Based on these representations, our dynamic learning module (world model) have the SOTA performance on both accuracy and efficiency (right figure).
Check our paper for further information!
Semantic occupancy forecasting Visualization
Our proposed module have better performance in both agent trajectory forcasting and physical/semantic consistency. In most cases, our model provides more accurate estimates of the surrounding objects velocity and better spatio-temporal consistency.


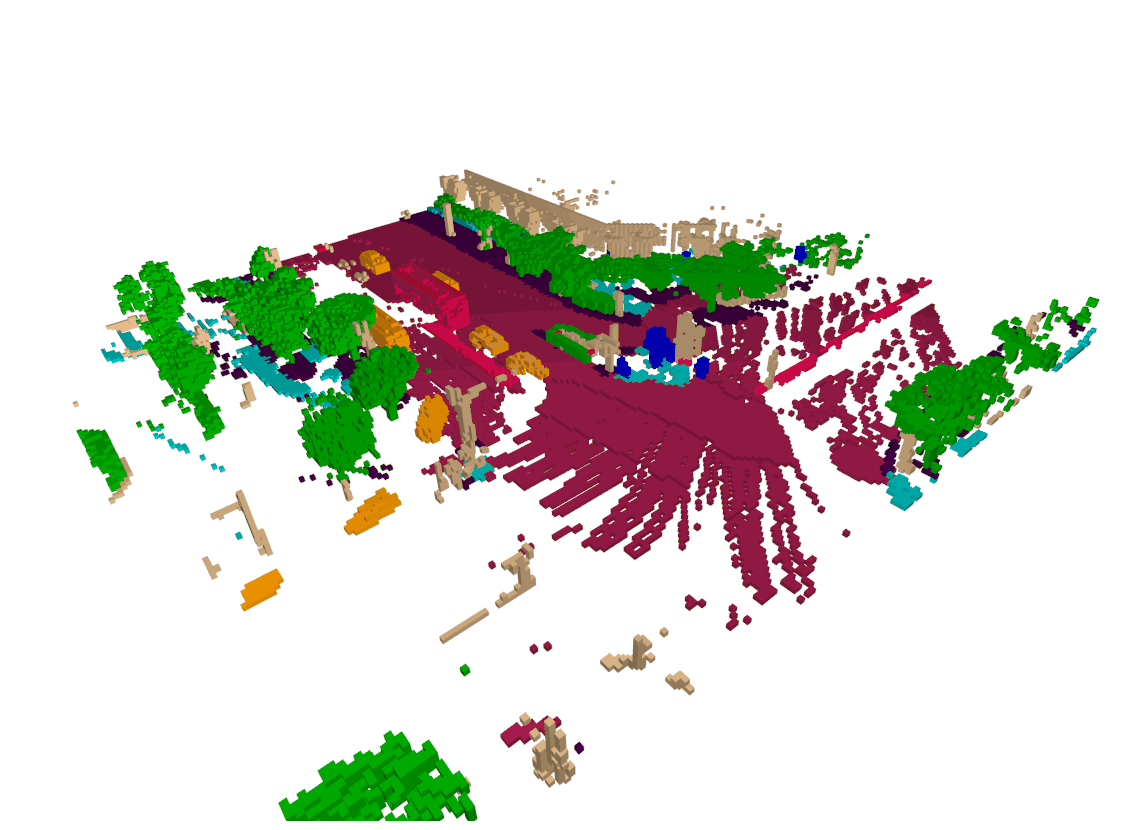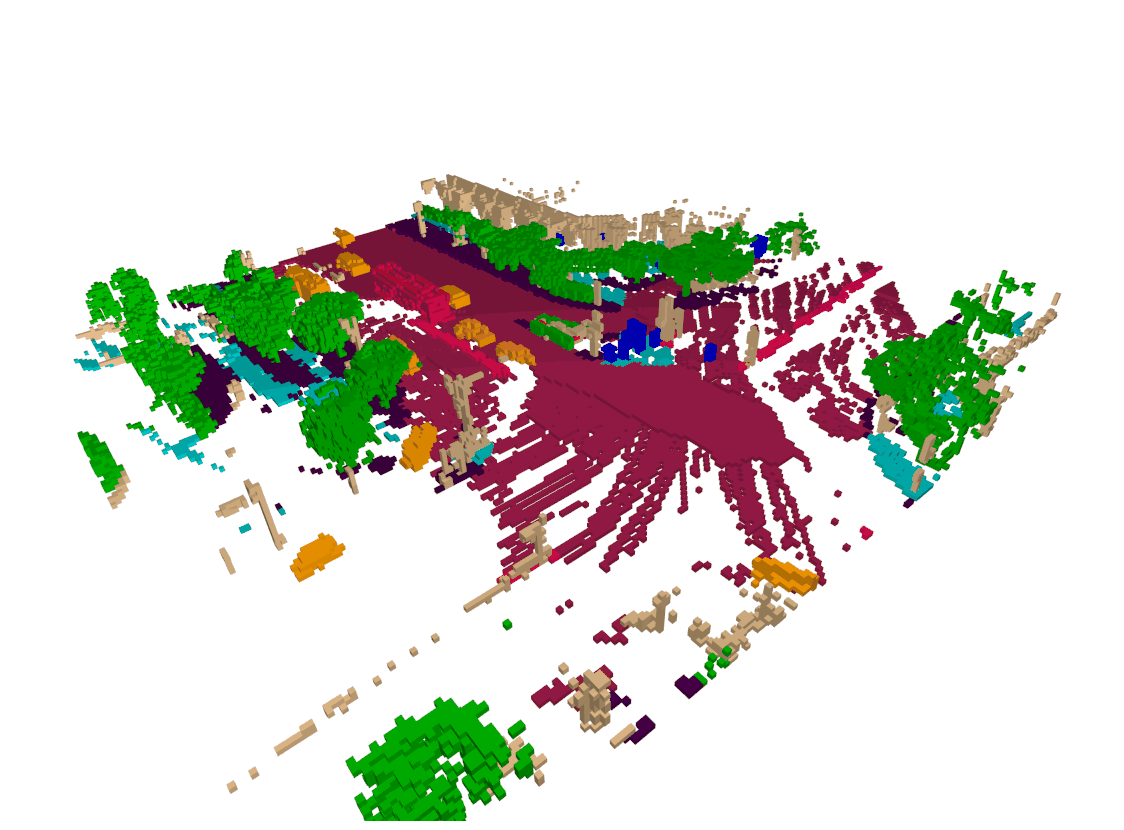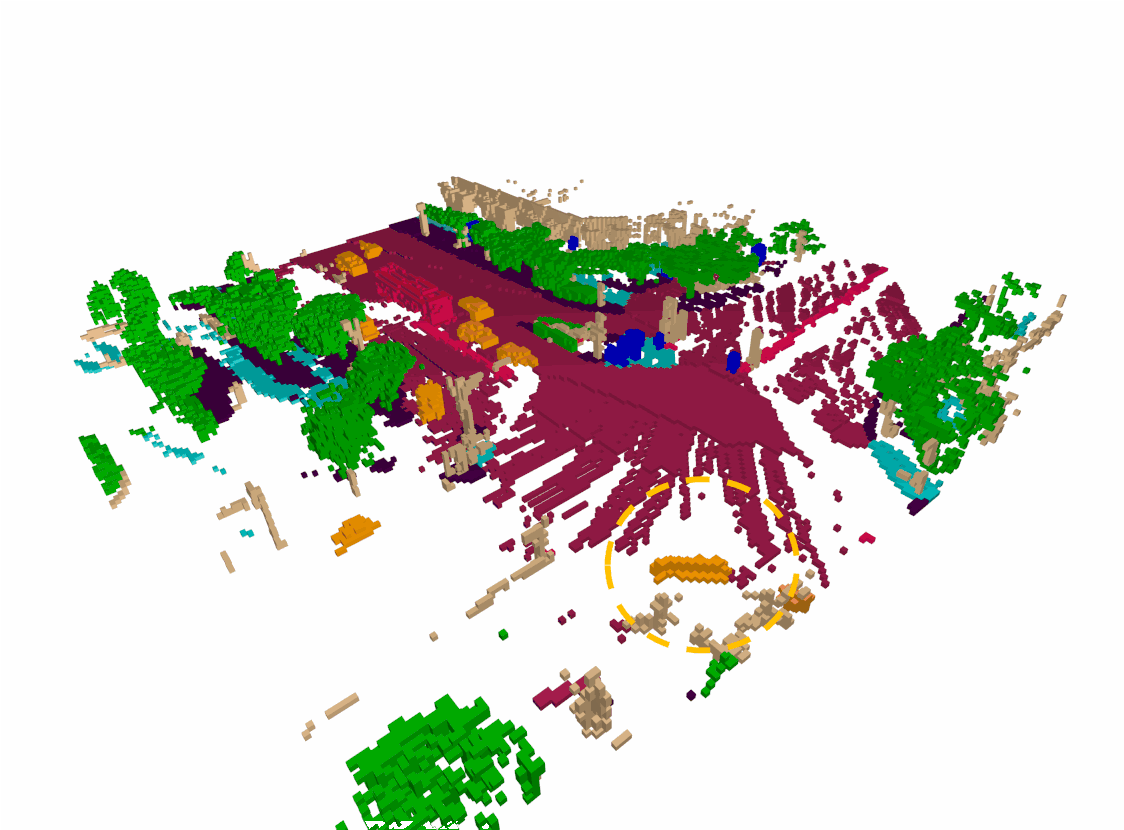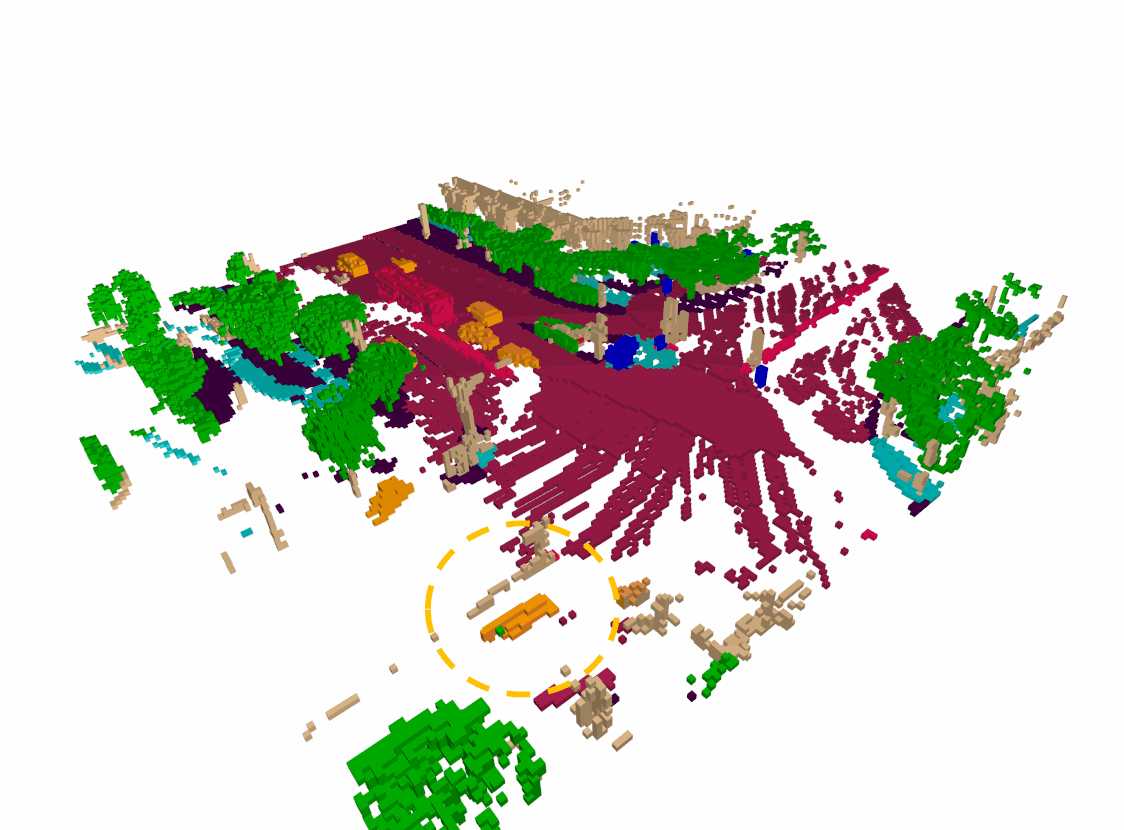













Dense & Sparse occupancy forecasting (Pretrain) Visualization
We also present the result of pretraining, our model can learn the dynamic knowledge on both sparse and dense non-semantic occupancy.
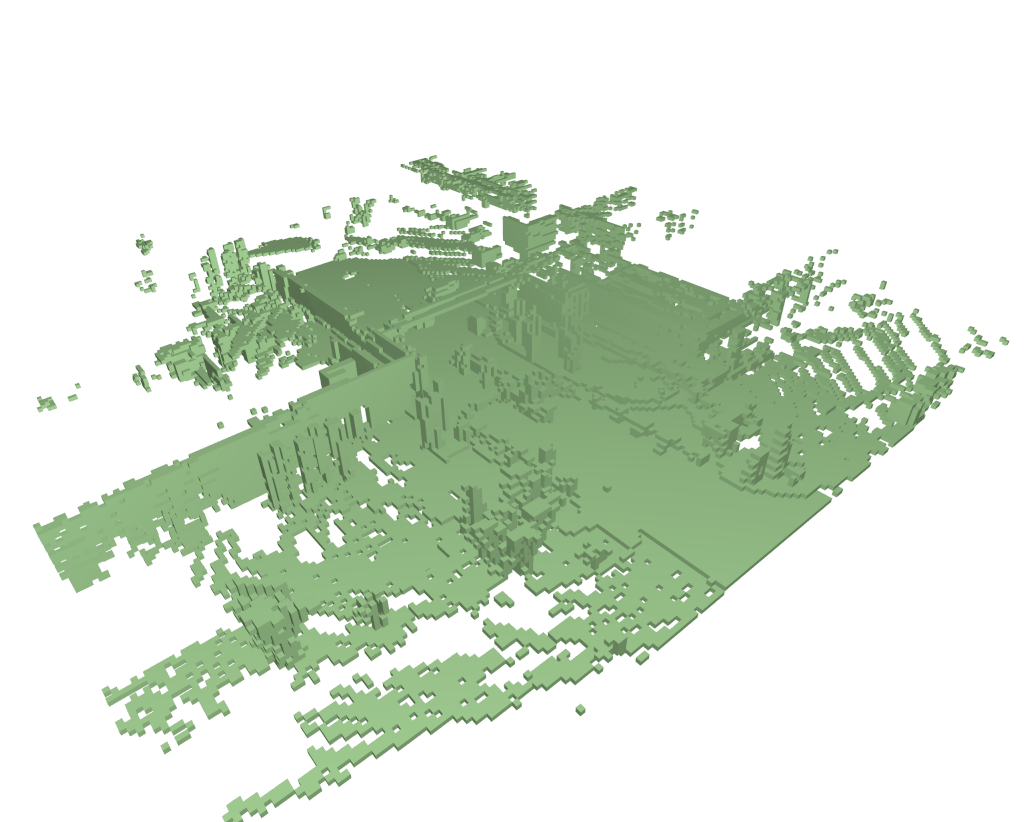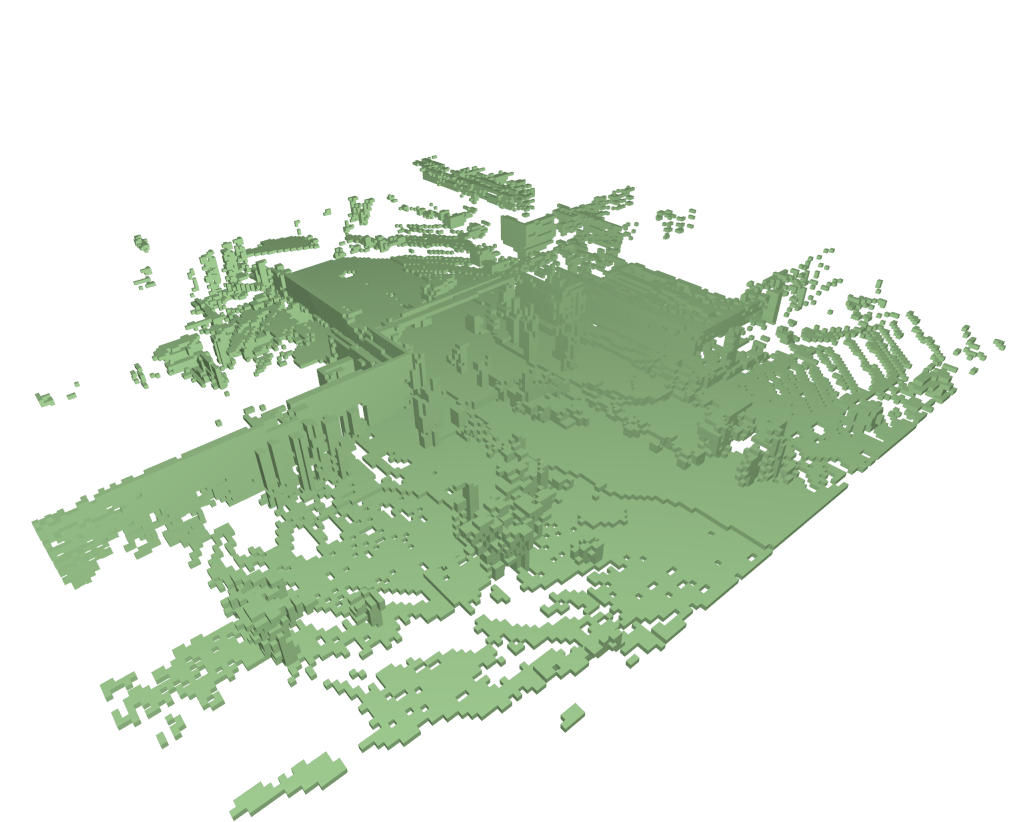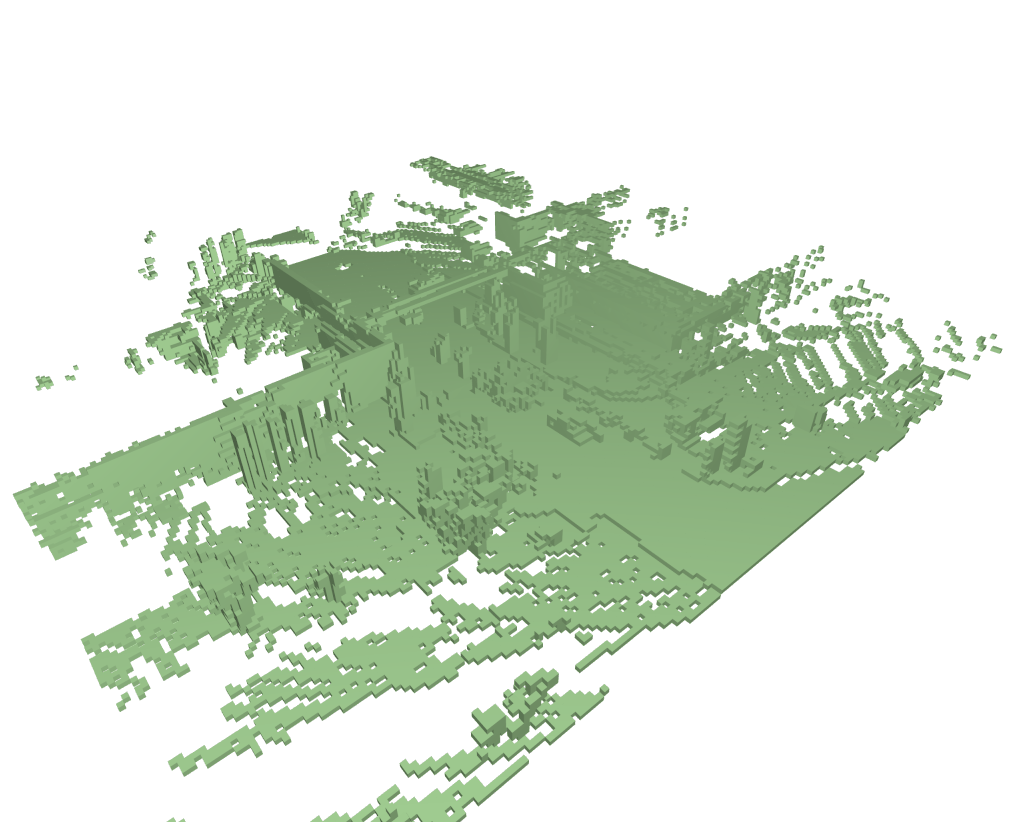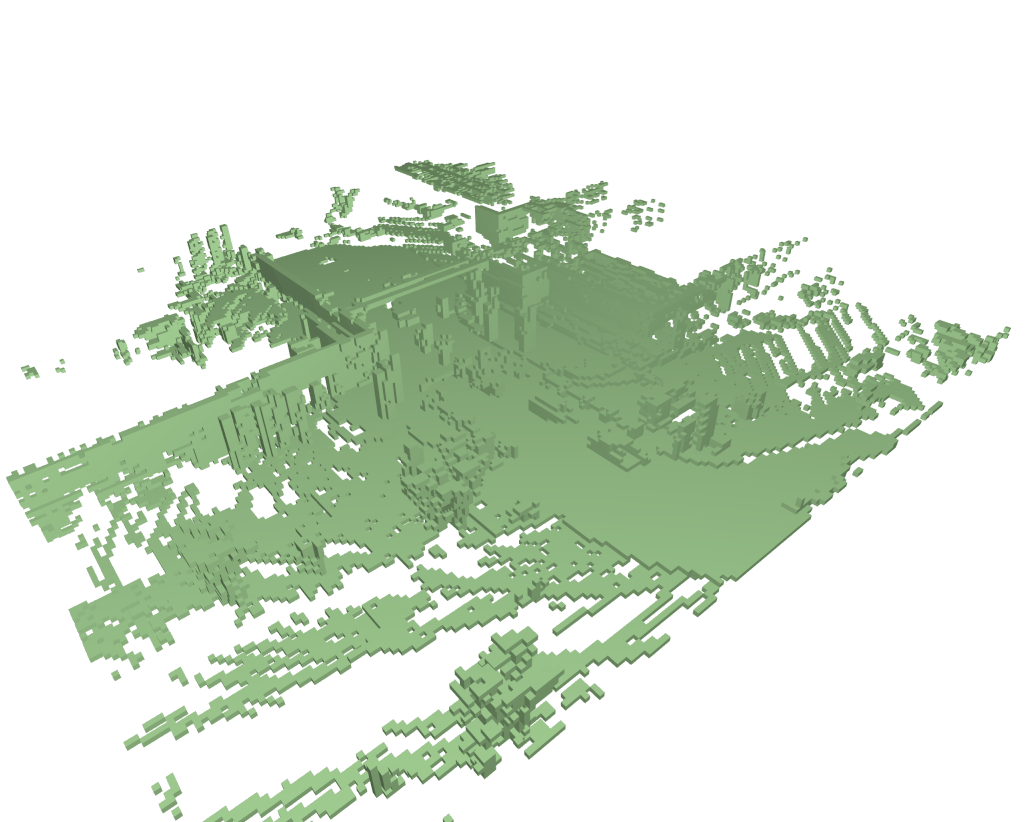



BibTeX
@article{liu2025xxxx,
title = {Towards foundational LiDAR world models with efficient latent flow matching},
author = {Tianran Liu, Shenwen Zhao and Nicholas Rhinehart},
journal = {arXiv preprint arXiv:xxxx},
year = {2025}
}